
Giám đốc điều hành Nvidia Jensen Huang tuần trước đã tham gia podcast của Lex Fridman và thẳng thắn nói, "Tôi nghĩ chúng ta đã đạt được AGI." Hai ngày sau, bài kiểm tra nghiêm ngặt nhất trong nghiên cứu AI đã công bố tiêu chuẩn trí tuệ nhân tạo tổng quát mới nhất của mình—và mọi mô hình tiên tiến đều đạt dưới 1%.
Quỹ ARC Prize đã phát hành ARC-AGI-3 trong tuần này, và kết quả thật phũ phàng. Gemini 3.1 Pro của Google dẫn đầu với 0.37%. GPT-5.4 của OpenAI đạt 0.26%. Claude Opus 4.6 của Anthropic đạt 0.25%, trong khi Grok-4.20 của xAI đạt chính xác 0%. Trong khi đó, con người đã giải quyết 100% các môi trường.
Đây không phải là một bài kiểm tra kiến thức tổng quát hay bài thi lập trình, hoặc thậm chí là các câu hỏi cực khó cấp độ tiến sĩ. ARC-AGI-3 là một cái gì đó hoàn toàn khác biệt so với bất cứ điều gì ngành công nghiệp AI đã từng đối mặt trước đây.
Tiêu chuẩn này được xây dựng bởi quỹ của François Chollet và Mike Knoop, họ đã thành lập một studio trò chơi nội bộ và tạo ra 135 môi trường tương tác nguyên bản từ đầu. Ý tưởng là đưa một tác nhân AI vào một thế giới giống trò chơi không quen thuộc mà không có hướng dẫn, không có mục tiêu cụ thể và không có mô tả quy tắc. Tác nhân phải khám phá, tìm ra những gì nó cần làm, lập kế hoạch và thực hiện nó.
Nếu điều đó nghe có vẻ là thứ mà một đứa trẻ năm tuổi cũng có thể làm được, thì bạn đang bắt đầu hiểu vấn đề rồi đấy. Nếu bạn muốn xem liệu mình có giỏi hơn AI hay không, bạn có thể chơi các trò chơi tương tự trong bài kiểm tra bằng cách nhấp vào liên kết này. Chúng tôi đã thử một trò; ban đầu nó hơi lạ, nhưng sau vài giây, bạn có thể dễ dàng nắm bắt được cách chơi.
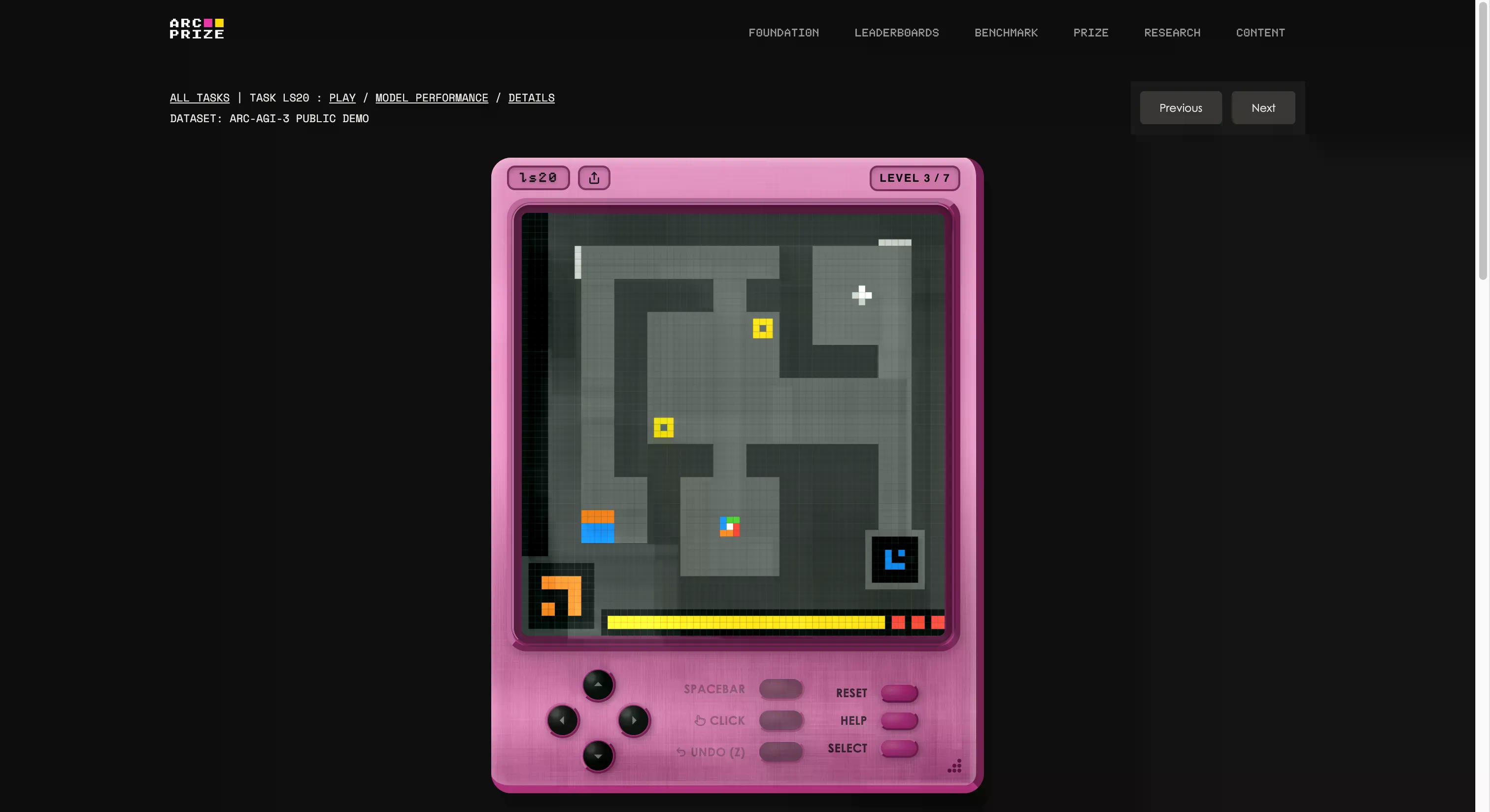
Đây cũng là ví dụ rõ ràng nhất về ý nghĩa của chữ "G" trong AGI. Khi bạn khái quát hóa, bạn có thể tạo ra kiến thức mới (cách một trò chơi kỳ lạ hoạt động) mà không cần được huấn luyện trước về nó.
Các phiên bản trước của ARC đã kiểm tra các câu đố hình ảnh tĩnh—hiển thị một mẫu, dự đoán mẫu tiếp theo. Ban đầu chúng rất khó. Sau đó, các phòng thí nghiệm đã đổ công suất tính toán và huấn luyện vào chúng cho đến khi các tiêu chuẩn này thực sự trở nên vô nghĩa. ARC-AGI-1, ra mắt vào năm 2019, đã bị "khuất phục" bởi các mô hình huấn luyện và lập luận trong thời gian kiểm tra. ARC-AGI-2 tồn tại khoảng một năm trước khi Gemini 3.1 Pro đạt 77.1%. Các phòng thí nghiệm rất giỏi trong việc bão hòa các tiêu chuẩn mà họ có thể huấn luyện.
Phiên bản 3 được thiết kế đặc biệt để ngăn chặn điều đó. Với 110 trong số 135 môi trường được giữ riêng tư—55 môi trường bán riêng tư để thử nghiệm API, 55 môi trường hoàn toàn bị khóa cho cuộc thi—không có bộ dữ liệu nào để ghi nhớ. Bạn không thể dùng sức mạnh tính toán để giải quyết một logic trò chơi mới mà bạn chưa từng thấy.
Việc chấm điểm cũng không phải là đậu/rớt. ARC-AGI-3 sử dụng cái mà quỹ gọi là RHAE—Hiệu quả Hành động Tương đối của Con người. Điểm cơ bản là hiệu suất tốt thứ hai của con người trong lần chạy đầu tiên. Một AI thực hiện số hành động gấp mười lần con người sẽ đạt 1% cho cấp độ đó, không phải 10%. Công thức này bình phương hình phạt cho sự kém hiệu quả. Việc đi lòng vòng, quay lại và đoán mò để tìm ra câu trả lời sẽ bị phạt rất nặng.
Tác nhân AI tốt nhất trong bản xem trước dành cho nhà phát triển kéo dài một tháng đã đạt 12.58%. Các LLM tiên tiến được thử nghiệm thông qua API chính thức, không có công cụ tùy chỉnh, không thể vượt qua 1%. Con người bình thường đã giải quyết tất cả 135 môi trường mà không cần huấn luyện trước và không có hướng dẫn. Nếu đó là tiêu chuẩn, thì các mô hình hiện tại không đạt được nó.
Có một cuộc tranh luận về phương pháp luận thực sự ở đây. Báo cáo của ARC nói rằng một công cụ tùy chỉnh do Duke xây dựng đã đẩy Claude Opus 4.6 từ 0.25% lên 97.1% trên một biến thể môi trường duy nhất có tên TR87. Điều đó không có nghĩa là Claude đạt 97.1% trên toàn bộ ARC-AGI-3; điểm chuẩn chính thức của nó vẫn là 0.25%, nhưng sự thay đổi này vẫn đáng chú ý.
Tiêu chuẩn chính thức cung cấp cho các tác nhân mã JSON, chứ không phải hình ảnh. Đó có thể là một lỗi phương pháp luận hoặc là một minh chứng rằng các mô hình hiện nay tốt hơn trong việc xử lý thông tin thân thiện với con người hơn là dữ liệu có cấu trúc thô. Quỹ của Chollet đã thừa nhận cuộc tranh luận này, nhưng không thay đổi định dạng.
Báo cáo viết rằng: "Nhận thức nội dung khung hình và định dạng API không phải là yếu tố hạn chế hiệu suất của mô hình tiên tiến trên ARC-AGI-3". Nói cách khác, họ dường như bác bỏ ý kiến cho rằng các mô hình thất bại vì chúng "không thể nhìn thấy" các nhiệm vụ một cách chính xác, thay vào đó lập luận rằng nhận thức đã đủ—và khoảng cách thực sự nằm ở khả năng lập luận và khái quát hóa.
Thực tế kiểm chứng về AGI đã xuất hiện trong một tuần mà cỗ máy thổi phồng đang hoạt động hết công suất. Ngoài bình luận của Huang, Arm đã đặt tên chip trung tâm dữ liệu mới của mình là "AGI CPU." Sam Altman của OpenAI đã nói rằng họ "về cơ bản đã xây dựng AGI," và Microsoft đã và đang quảng bá một phòng thí nghiệm tập trung vào việc xây dựng ASI: Một sự phát triển của những gì đến sau khi AGI đạt được. Có vẻ như thuật ngữ này đang bị kéo giãn cho đến khi nó có nghĩa là bất cứ điều gì thuận tiện về mặt thương mại.
Quan điểm của Chollet đơn giản hơn. Nếu một người bình thường không có hướng dẫn có thể làm được, mà hệ thống của bạn không thể, thì bạn không có AGI—bạn chỉ có một chức năng tự động hoàn thành rất đắt tiền cần rất nhiều sự trợ giúp.
ARC Prize 2026 đang trao giải thưởng 2 triệu USD trên ba hạng mục thi đấu, tất cả đều được tổ chức trên Kaggle. Mọi giải pháp chiến thắng phải được công khai mã nguồn. Đồng hồ đang chạy, và hiện tại, các cỗ máy thậm chí còn chưa đến gần.