
Nvidia के CEO जेन्सेन हुआंग पिछले हफ्ते लेक्स फ्रिडमैन के पॉडकास्ट में गए और साफ-साफ कहा, "मुझे लगता है कि हमने AGI हासिल कर लिया है।" दो दिन बाद, AI अनुसंधान के सबसे कठोर परीक्षण ने अपना नवीनतम आर्टिफिशियल जनरल इंटेलिजेंस बेंचमार्क जारी किया - और हर अग्रणी मॉडल ने 1% से कम स्कोर किया।
ARC प्राइज़ फाउंडेशन ने इस सप्ताह ARC-AGI-3 जारी किया, और परिणाम बहुत खराब रहे। Google का जेमिनी 3.1 प्रो 0.37% के साथ सबसे आगे रहा। OpenAI का GPT-5.4 0.26% पर रहा। एंथ्रोपिक के क्लाउड ओपस 4.6 ने 0.25% का प्रबंधन किया, जबकि xAI के ग्रॉक-4.20 ने ठीक शून्य स्कोर किया। इस बीच, मनुष्यों ने 100% वातावरण को हल किया।
यह कोई सामान्य ज्ञान का परीक्षण या कोडिंग परीक्षा नहीं है, और न ही यह पीएचडी स्तर के अत्यधिक कठिन प्रश्न हैं। ARC-AGI-3 AI उद्योग द्वारा पहले सामना की गई किसी भी चीज़ से पूरी तरह अलग है।
यह बेंचमार्क फ्रांकोइस चोलेट और माइक नूप के फाउंडेशन द्वारा बनाया गया था, जिसने एक इन-हाउस गेम स्टूडियो स्थापित किया और खरोंच से 135 मूल इंटरैक्टिव वातावरण बनाए। विचार यह है कि एक AI एजेंट को एक अपरिचित गेम-जैसे दुनिया में बिना किसी निर्देश, बिना किसी निर्धारित लक्ष्य और नियमों के विवरण के छोड़ा जाए। एजेंट को खोजना होगा, यह पता लगाना होगा कि उसे क्या करना है, एक योजना बनानी होगी और उसे क्रियान्वित करना होगा।
अगर यह ऐसा लगता है जो कोई भी पाँच साल का बच्चा कर सकता है, तो आप समस्या को समझना शुरू कर रहे हैं। यदि आप देखना चाहते हैं कि आप AI से बेहतर हैं या नहीं, तो आप इस लिंक पर क्लिक करके परीक्षण में शामिल वही गेम खेल सकते हैं। हमने एक कोशिश की; पहले तो यह अजीब लगा, लेकिन कुछ ही सेकंड में आपको इसकी आदत हो जाएगी।
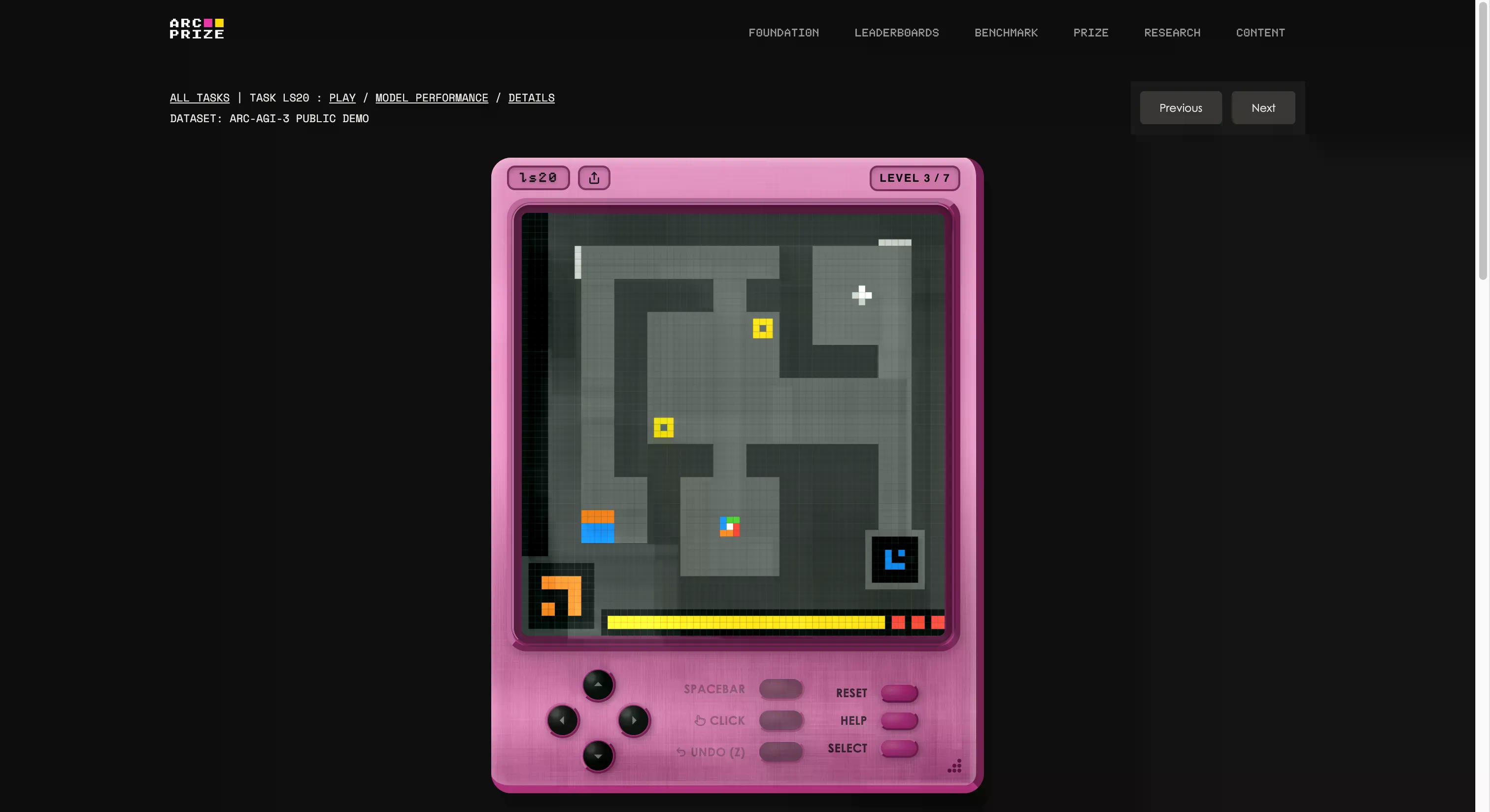
यह इस बात का भी सबसे स्पष्ट उदाहरण है कि AGI में "G" किस लिए है। जब आप सामान्यीकरण करते हैं, तो आप पहले से प्रशिक्षित हुए बिना नया ज्ञान (जैसे कोई अजीब खेल कैसे काम करता है) बनाने में सक्षम होते हैं।
ARC के पिछले संस्करणों ने स्थिर दृश्य पहेलियों का परीक्षण किया था - एक पैटर्न दिखाओ, अगले की भविष्यवाणी करो। वे पहले मुश्किल थे। फिर प्रयोगशालाओं ने उन पर कंप्यूट शक्ति और प्रशिक्षण झोंक दिया जब तक कि बेंचमार्क प्रभावी रूप से अप्रभावी नहीं हो गए। 2019 में पेश किया गया ARC-AGI-1, टेस्ट-टाइम प्रशिक्षण और तर्क मॉडल के सामने ध्वस्त हो गया। ARC-AGI-2 लगभग एक साल तक चला, इससे पहले कि जेमिनी 3.1 प्रो ने 77.1% अंक हासिल किए। प्रयोगशालाएं उन बेंचमार्क को संतृप्त करने में बहुत अच्छी हैं जिनके खिलाफ वे प्रशिक्षित कर सकते हैं।
संस्करण 3 को विशेष रूप से इसे रोकने के लिए डिज़ाइन किया गया था। 135 वातावरणों में से 110 को निजी रखा गया - 55 API परीक्षण के लिए अर्ध-निजी, 55 प्रतियोगिता के लिए पूरी तरह से बंद - याद करने के लिए कोई डेटासेट नहीं है। आप उस नए गेम लॉजिक को brute-force नहीं कर सकते जिसे आपने कभी नहीं देखा।
स्कोरिंग भी पास/फेल नहीं है। ARC-AGI-3 वह उपयोग करता है जिसे फाउंडेशन RHAE - रिलेटिव ह्यूमन एक्शन एफिशिएंसी कहता है। आधारभूत रेखा दूसरा सबसे अच्छा, पहली बार का मानव प्रदर्शन है। एक AI जो मानव की तुलना में दस गुना अधिक क्रियाएँ करता है, उस स्तर के लिए 1% स्कोर करता है, 10% नहीं। सूत्र अक्षमता के लिए दंड को वर्गित करता है। इधर-उधर भटकना, पीछे हटना और अनुमान लगाकर उत्तर तक पहुँचना बहुत कठोरता से दंडित किया जाता है।
एक महीने के डेवलपर पूर्वावलोकन में सर्वश्रेष्ठ AI एजेंट ने 12.58% स्कोर किया। आधिकारिक API के माध्यम से परीक्षण किए गए फ्रंटियर LLM, बिना किसी कस्टम टूलिंग के, 1% भी नहीं भेद पाए। साधारण मनुष्यों ने बिना किसी पूर्व प्रशिक्षण और निर्देशों के सभी 135 वातावरणों को हल किया। यदि यह पैमाना है, तो मॉडल का वर्तमान समूह इसे पार नहीं कर रहा है।
यहाँ एक वास्तविक पद्धतिगत बहस है। ARC की रिपोर्ट कहती है कि ड्यूक द्वारा निर्मित एक कस्टम हार्नेस ने Claude Opus 4.6 को TR87 नामक एक ही वातावरण वेरिएंट पर 0.25% से 97.1% तक पहुँचाया। इसका मतलब यह नहीं है कि क्लाउड ने ARC-AGI-3 पर कुल मिलाकर 97.1% स्कोर किया; इसका आधिकारिक बेंचमार्क स्कोर 0.25% ही रहा, लेकिन इस बदलाव पर ध्यान देना अभी भी महत्वपूर्ण है।
आधिकारिक बेंचमार्क एजेंटों को JSON कोड प्रदान करता है, न कि दृश्य। यह या तो एक पद्धतिगत खामी है या यह प्रदर्शन कि आज के मॉडल कच्चे संरचित डेटा की तुलना में मानव-अनुकूल जानकारी को संसाधित करने में बेहतर हैं। चोलेट के फाउंडेशन ने इस बहस को स्वीकार किया है, लेकिन प्रारूप नहीं बदल रहा है।
पेपर में लिखा है, "फ्रेम सामग्री की धारणा और एपीआई प्रारूप ARC-AGI-3 पर अग्रणी मॉडल प्रदर्शन के लिए सीमित कारक नहीं हैं।" दूसरे शब्दों में, वे इस विचार को खारिज करते हुए प्रतीत होते हैं कि मॉडल इसलिए विफल होते हैं क्योंकि वे कार्यों को ठीक से "देख नहीं सकते", इसके बजाय यह तर्क देते हैं कि धारणा पहले से ही पर्याप्त है - और वास्तविक अंतर तर्क और सामान्यीकरण में निहित है।
AGI वास्तविकता की जाँच उस सप्ताह हुई जब प्रचार मशीन पूरी गति से चल रही थी। हुआंग की टिप्पणी के अलावा, आर्म ने अपने नए डेटा सेंटर चिप को "AGI CPU" नाम दिया। OpenAI के सैम ऑल्टमैन ने कहा है कि उन्होंने "मूल रूप से AGI बनाया है," और माइक्रोसॉफ्ट पहले से ही ASI बनाने पर केंद्रित एक लैब का विपणन कर रहा है: AGI हासिल होने के बाद आने वाले का एक विकास। ऐसा प्रतीत होता है कि इस शब्द को तब तक खींचा जा रहा है जब तक कि इसका मतलब वह सब कुछ न हो जाए जो व्यावसायिक रूप से सुविधाजनक है।
चोलेट की स्थिति सरल है। यदि कोई सामान्य मनुष्य बिना किसी निर्देश के इसे कर सकता है, और आपका सिस्टम नहीं कर सकता, तो आपके पास AGI नहीं है - आपके पास एक बहुत महंगा ऑटोकंप्लीट है जिसे बहुत मदद की ज़रूरत है।
ARC प्राइज़ 2026 तीन प्रतियोगिता ट्रैकों में 2 मिलियन डॉलर प्रदान कर रहा है, सभी Kaggle पर होस्ट किए गए हैं। प्रत्येक विजेता समाधान को ओपन-सोर्स किया जाना चाहिए। घड़ी चल रही है, और अभी, मशीनें कहीं भी पास नहीं हैं।